Apache Ambari Infra Solr and Apache Ranger - Fixing OOM
Update - 2017-12-21
- Added Ambari JIRA link
Update - 2017-12-19
- Fixed some content and formatting
- Added external links
Overview
When using Apache Ranger, Apache Ambari Infra Solr (or any Apache Solr that Ranger is pointing at) crashes with Java OOM killer even with increased Java heap. Increasing the heap makes the problem take longer to occur, but eventually (sometimes coinciding with a TTL deletion) a Solr OOM error occurs. Other users have reported the same issue for example here.
This blog is organized into the following sections:
- Diagnosing the problem
- Understanding the problem
- Fixing the problem
Diagnosing the problem
There are a few ways to diagnosis this is happening:
/var/log/ambari-infra-solr/solr_oom_killer-8886*- If a file called
/var/log/ambari-infra-solr/solr_oom_killer-8886*is present, this means that the Solr OOM killer ran when there was a GC error. - The file name has the time of when Solr crashed.
- If a file called
- Analyzing the garbage collection (GC) logs
- GCViewer (https://github.com/chewiebug/GCViewer) can analyze the Solr GC logs
- Solr GC logs are typically available here:
/var/log/ambari-infra-solr/solr_gc.log - The output below is typical of the GC logs where this occurs regardless of the heap size.
- The heap looks normal with tenured increasing overtime. At some point, the heap increases drastically with full GC pauses. At this point, Solr crashes due to OOM.
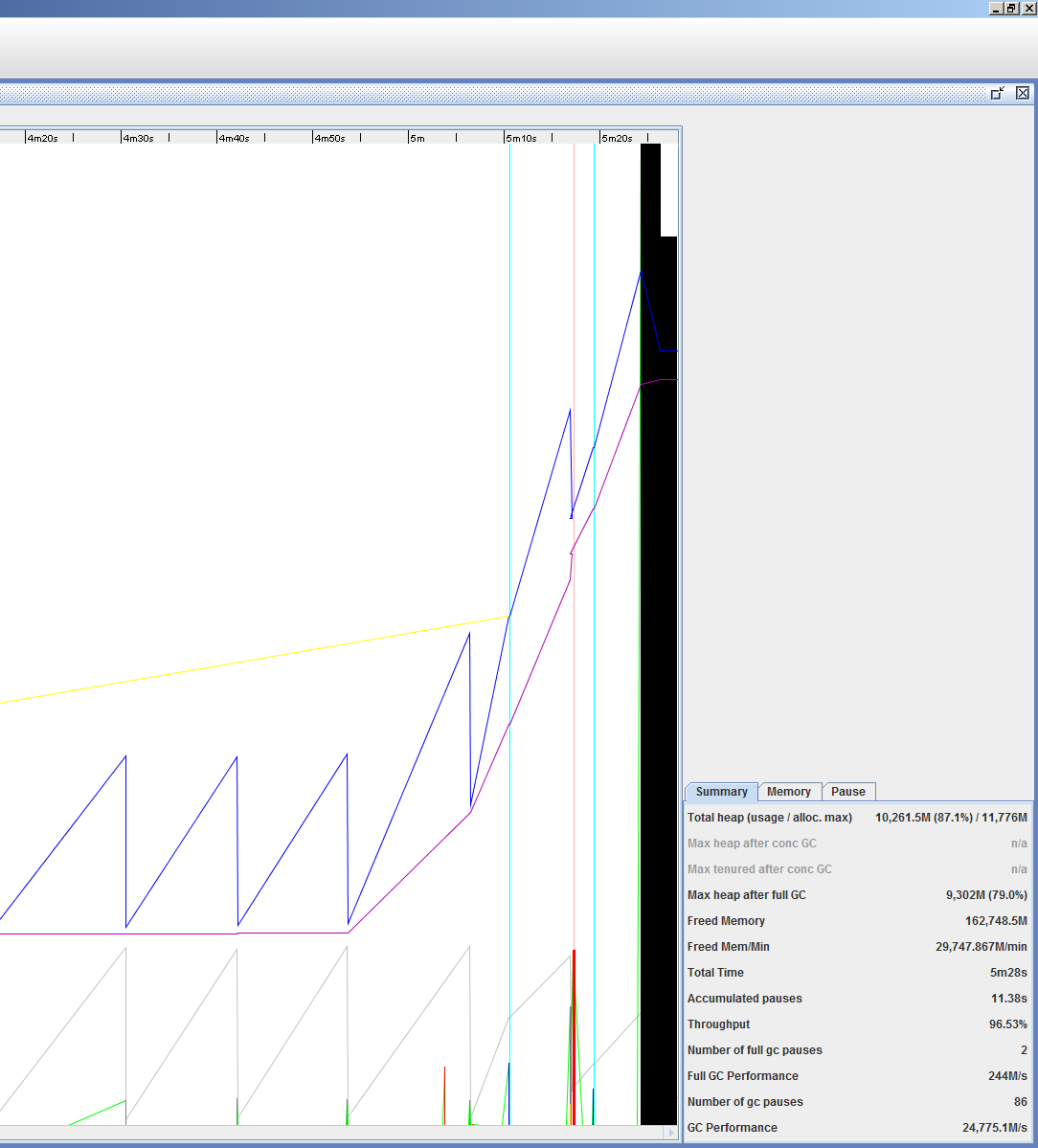
- The heap looks normal with tenured increasing overtime. At some point, the heap increases drastically with full GC pauses. At this point, Solr crashes due to OOM.
- Analyze a heap dump
- If Solr is running, you can generate a heap dump showing what makes up the heap space.
- The heap dump file will be approximately as big as the heap setting. For example, 8GB heap = ~8GB heap dump file
- Generate the heap dump with
jmap -dump:format=b,file=solr_heap_dump.bin <pid>- This should be run as the infra-solr user or the user who is running Solr
- The pid can be determined by
ps aux | grep solr - Once the heap dump file has been generated, you can analyze it with heap analyzer tools like Eclipse Memory Analyzer (https://www.eclipse.org/mat/)
- An example of analyzing the heap before fixing is:
- Most of the heap is used by the
org.apache.lucene.uninverting.FieldCache…class objects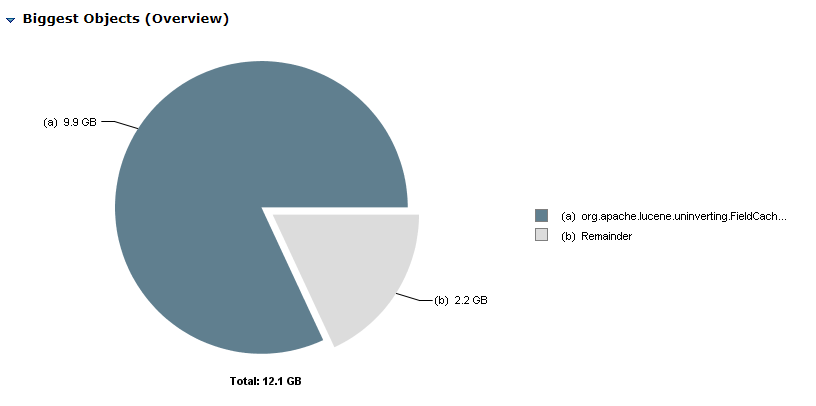
- Most of the heap is used by the
- Generate the heap dump with
- Reviewing the Solr Cache Stats
- If Solr is running, you can view the Solr Cache stats here:
- The
entries_countandentry#...will show how much heap each entry is taking up. - In the example below, the
_version_field is uninverted multiple times taking up ~300MB of space for each entry.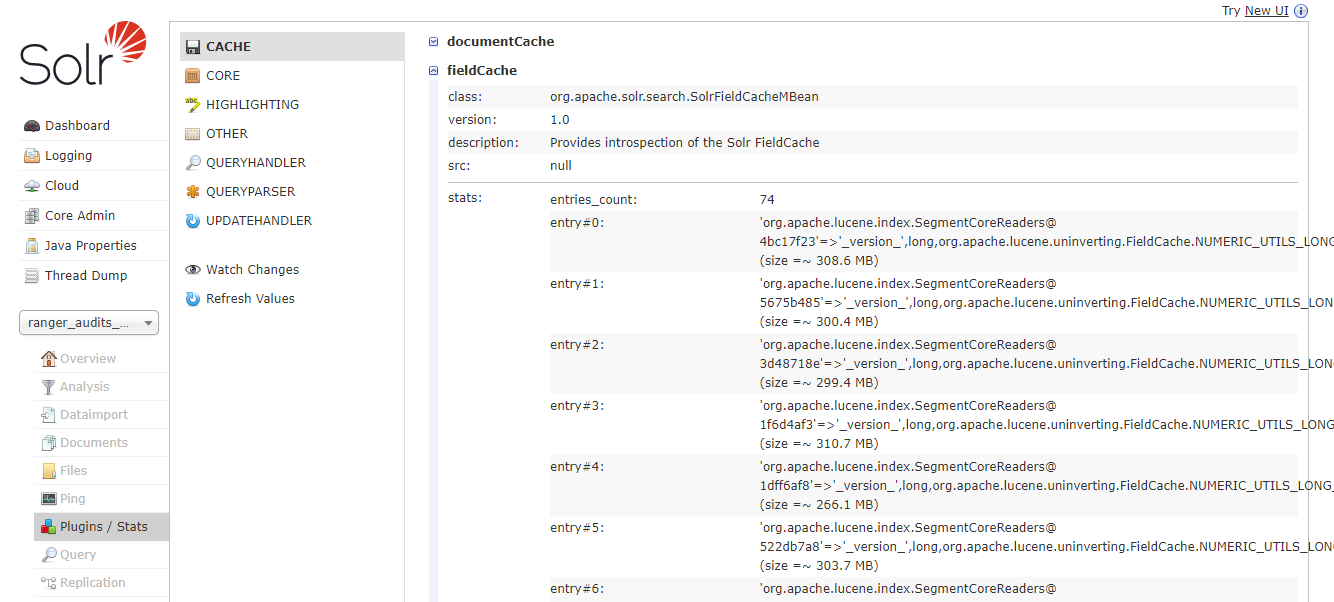
Understanding the problem
Apache Solr uses Lucene to store fields in an inverted index. This works great for full text search and finding documents quickly. For sorting and faceting, Solr must instead deal with the uninverted value instead of the inverted value. There are two ways that Solr does this:
- If the field is indexed, Solr can uninvert the field on heap and store it in the fieldCache. This takes query time to generate the first time and heap to store the result.
- If the field has docValues enabled, Solr stores the uninverted value at index time. This takes index time to save but when used in a query there is no heap usage since the values can be read from disk/OS memory.
Apache Lucene introduced DocValues in version 4.0. Apache Solr has adopted support for DocValues throughout the 4.x, 5.x, and 6.x releases. The defaults changed from no DocValues in 4.x to most fields having DocValues enabled by 6.x. Apache Solr 5.5.x has support for DocValues just like 6.x as well just with different defaults for fields in collections.
Apache Ranger has a schema that does not have DocValues enabled for the _version_ field. This means that if there is a query like TTL deletion that requires the _version_ field, Solr must uninvert the _version_ field on heap. This is done for each version of the index and causes Solr to run out of heap memory. As the number of documents grows for Ranger Audit in Solr, the more heap space uninverting the _version_ field takes up. Increasing the Solr heap will only help a bit until more _version_ fields are stored or more documents are indexed (each one having a _version_ value to keep track of)
Fixing the problem
Apache Ambari Infra Solr is just packaged Apache Solr 5.5.x. Solr 5.5.x has support for DocValues for most fields including the _version_ field. Ranger 0.7.x (latest as of this writing) ships with Solr configuration files as part of the release (https://github.com/apache/ranger/tree/ranger-0.7/security-admin/contrib/solr_for_audit_setup/conf). These are the configurations used by Apache Solr to determine if DocValues is used. By default, DocValues is off for _version_ and some other fields.
With DocValues enabled for _version_, newly indexed documents will not have to uninvert the _version_ field when being queried. The changes made for primitive fields to use DocValues can also reduce heap usage. This significantly reduces the heap necessary for Solr when using Ranger.
The general steps to fix the above problem is to do the following:
- Download the existing Solr schema from Zookeeper (pre-edited files are already available here).
- Modify the Solr schema to enable DocValues on required fields
- Upload the modified Solr schema to Zookeeper
- Delete the Solr
ranger_auditscollection - Recreate the Solr
ranger_auditscollection
Specific commands for Ambari Infra Solr:
ssh into Ambari Infra Solr host
sudo -u infra-solr -i
# If using Kerberos
kinit -kt /etc/security/keytabs/ambari-infra-solr.service.keytab $(whoami)/$(hostname -f)
# Set environment for zkcli
source /etc/ambari-infra-solr/conf/infra-solr-env.sh
export SOLR_ZK_CREDS_AND_ACLS="${SOLR_AUTHENTICATION_OPTS}"
# Download from zookeeper and edit
#/usr/lib/ambari-infra-solr/server/scripts/cloud-scripts/zkcli.sh --zkhost "${ZK_HOST}" -cmd getfile /configs/ranger_audits/managed-schema managed-schema
# edits required:
# schema version to 1.6
# For the following fieldTypes add 'docValues="true"': date, double, float, int, long, tdate, tdates, tdouble, tdoubles, tfloat, tfloats, tint, tints, tlong, tlongs
# For `_version_` fieldType, set indexed=”false”
# OR
# Download pre-edited
#wget -O managed-schema https://gist.githubusercontent.com/risdenk/8cc8f722e200468f9aa536cee7979d06/raw/aa61053847b84e40c3bae8adf806e68b5a1408d3/managed-schema.xml
# Upload configuration back to Zookeeper
/usr/lib/ambari-infra-solr/server/scripts/cloud-scripts/zkcli.sh --zkhost "${ZK_HOST}" -cmd putfile /configs/ranger_audits/managed-schema managed-schema
# Delete and recreate the ranger_audits collection
# If using Kerberos, add "-u : --negotiate" to the curl commands below
curl -i "http://$(hostname -f):8886/solr/admin/collections?action=DELETE&name=ranger_audits"
curl -i "http://$(hostname -f):8886/solr/admin/collections?action=CREATE&name=ranger_audits&numShards=5&maxShardsPerNode=10"
Miscellaneous notes about Apache Solr and Apache Ranger
- I typically increase number of shards from 1 to at least 5 (this is done in the above curl
CREATEcommand).- Solr only supports an absolute max of ~2 billion (size of int) documents in a single shard due to Lucene max shard size. This is a practical limit of 1 billion since deletes count towards the total. Many Ambari Infra Solr installations have much more than 1 billion audit events in the default 90 day retention.
- A single Solr node can handle multiple shards (and collections).
- I also decrease the retention
TTLfrom 90 days to a few weeks to prevent too many documents being indexed in Solr.