Apache Solr - Leading Wildcard Queries and ReversedWildcardFilterFactory
Overview
Apache Solr is a full text search engine that is built on Apache Lucene. Recently, I was looking into performance where the query had leading wildcards. There have been many questions over the years about leading wildcard queries. It was surprising to me that there are few references explaining what leading wildcard queries are and how they are implemented behind the scenes. There are also no references that explain how to verify that leading wildcards are being processed efficiently.
So in this blog I cover the following:
- What are leading wildcard queries?
- Why are leading wildcard queries inefficient?
- How to improve leading wildcard queries
ReversedWildcardFilterFactoryImplementation
What are leading wildcard queries?
Leading wildcard queries are term queries that use the asterick (*) in the beginning of the term. For an example, you could look for all colors that end in ed with color:*ed. The asterick (*) takes the place of one or more characters. There is another variation where the question mark (?) is used as a placeholder for a single character. I am focusing on leading wildcard queries only and not trailing (ie: color:re*) or other combinations (ie: color:*e*). For more details, see the Apache Reference Guide Wildcard Searches page.
Why are leading wildcard queries inefficient?
Apache Lucene, the library that backs Apache Solr and Elasticsearch, is designed to search for tokens. Tokens are the representation of a piece of text data after it has been tokenized and analyzed. Lucene is very good at exact matches since it can efficiently query the index for matches. When leading wildcards are involved, there is a lot more work that needs to be done since the index is not optimized for this type of lookup.
A leading wildcard query must iterate through all of the terms in the index to see if they match the query. For even moderately sized indices this can be time consuming. With the asterick (*) at the beginning of the query, this means that there can be many matches throughout the index. The question mark (?) can be significantly more performant since Lucene doesn’t have to check as much. The iteration through the terms cannot stop until it has gone through the entire index for matches. This can cause poor caching if the index doesn’t fit in memory as well as other problems.
How to improve leading wildcard queries
The best way to improve leading wildcard queries is to remove them if possible. In many cases, there is a better way to handle the query by different tokenization or analyzing. If the use case requires leading wildcard queries then there is one trick that can help improve performance. One way to improve performance is to reverse the token during indexing which basically changes a leading wildcard query into a trailing wildcard query. A trailing wildcard query can be executed much more efficiently since only part of the index needs to be examined.
Apache Solr has a token filter called the ReversedWildcardFilterFactory that emits reversed tokens. This can be used when constructing fieldTypes for fields that may need to handle leading wildcard queries. There is an example of this in the _default config set called text_general_rev. This shows how to configure the ReversedWildcardFilterFactory for a field. It is important to note that the index and query analyzer phases are different. The ReversedWildcardFilterFactory MUST only be implemented as an index analyzer. The query side is handled automatically.
For reference, here is the text_general_rev fieldType definition:
<fieldType name="text_general_rev" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.ReversedWildcardFilterFactory" withOriginal="true"
maxPosAsterisk="3" maxPosQuestion="2" maxFractionAsterisk="0.33"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
ReversedWildcardFilterFactory Implementation
When the ReversedWildcardFilterFactory is setup for a field in Solr, the field has two different tokens emitted, original and reversed, during indexing. The screenshot below shows the Analysis tab showing how the token is created for a simple string abcdefg.
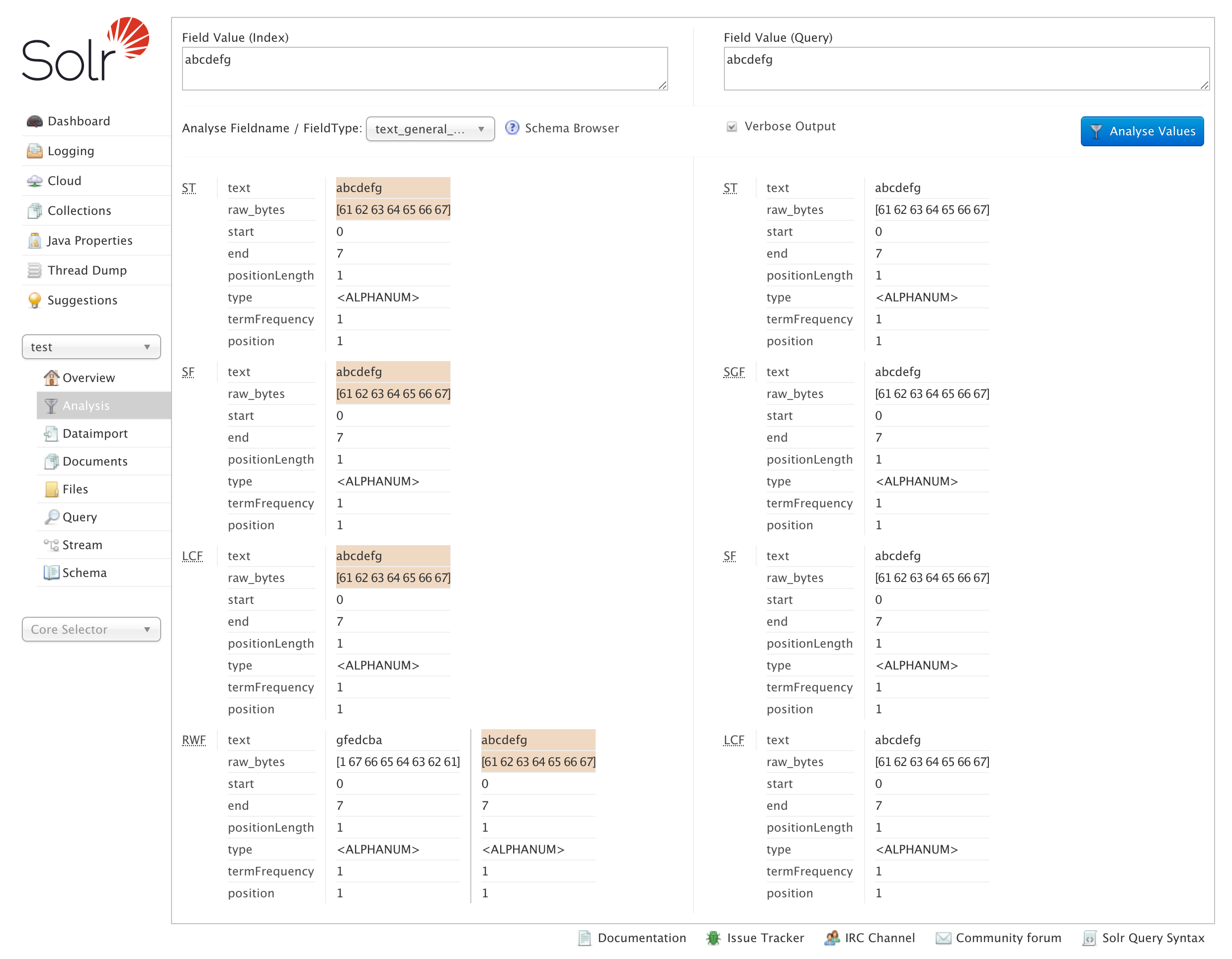
The extra reversed tokens will increase the index size, but this is usually an acceptable tradeoff since the other option is very slow leading wildcard queries.
When a query uses the field with ReversedWildcardFilterFactory, Solr internally evaluates whether to search for the original or reversed query string. One annoying part, since this optimization is internal to Solr, is that there is no indication to the user that the query string was reversed. Even with debug=true, the parsed query is the same since the AutomatonQuery#toString() method doesn’t provide information on the automaton. The screenshot below shows a leading wildcard query with no indication that it is working correctly.
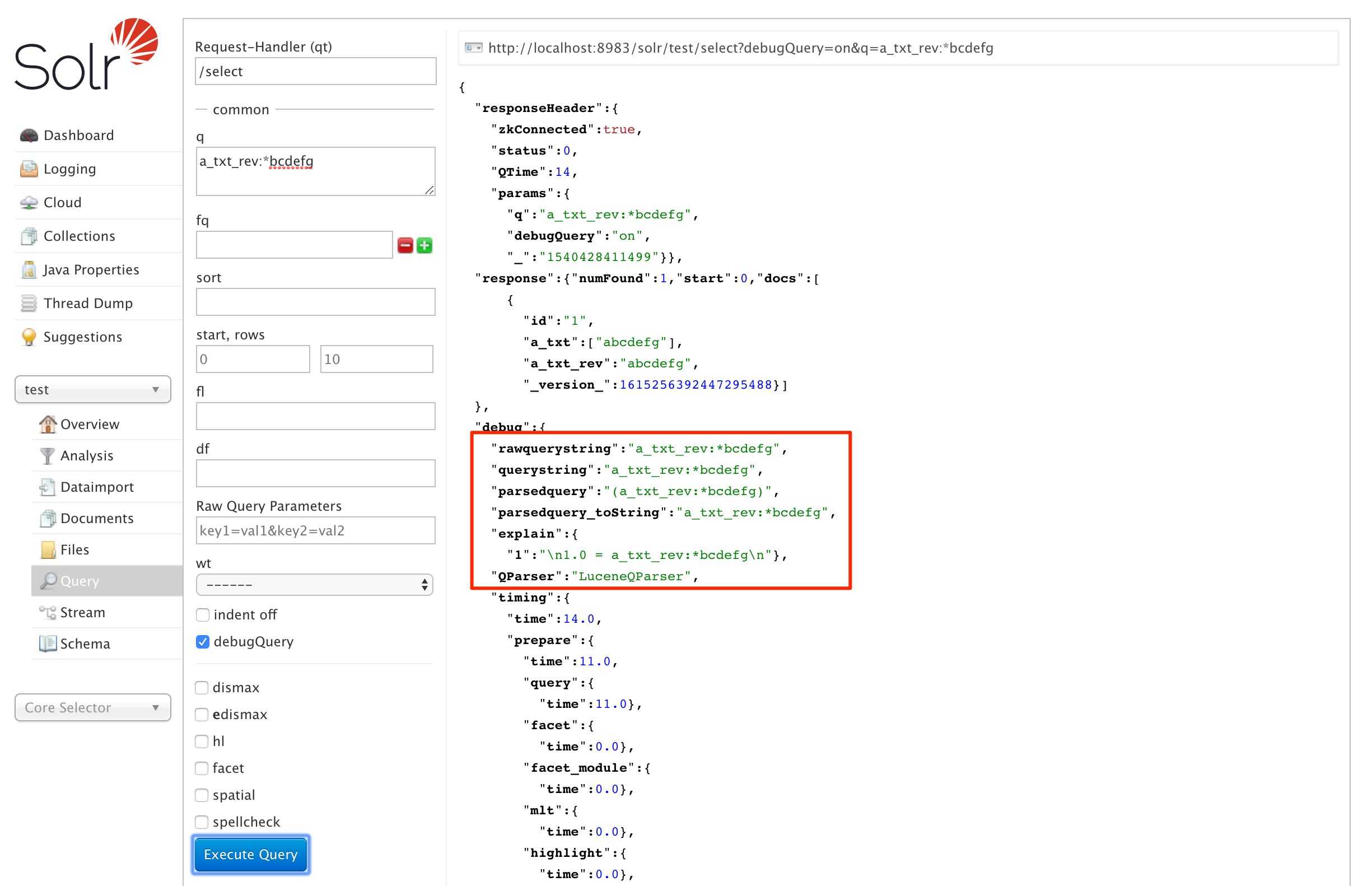
I was able to confirm the expected behavior by remotely debugging a running Solr server. This showed that the query was properly reversing the automaton based on the parameters for the ReversedWildcardFilterFactory.
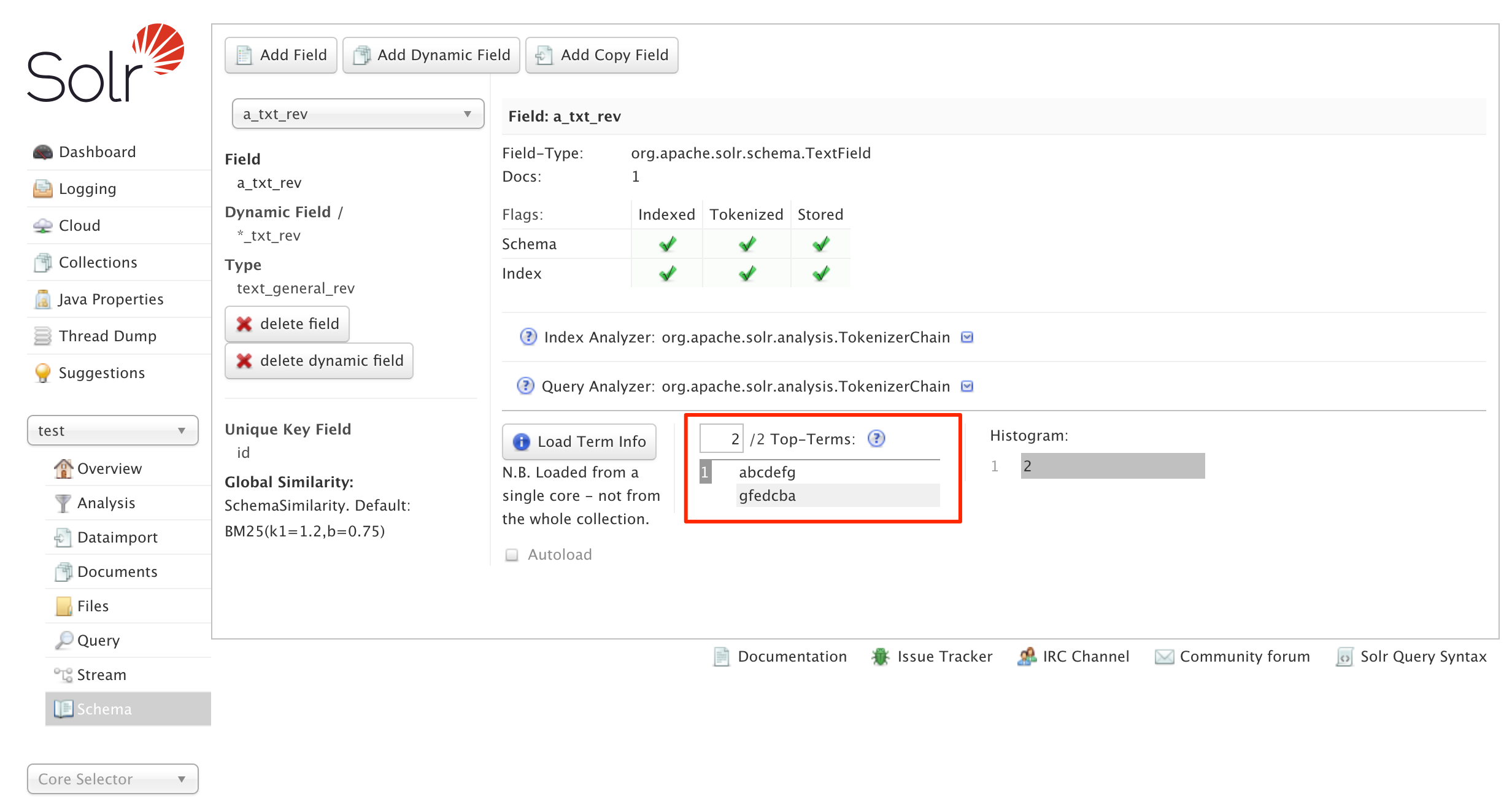
The only place I’ve been able to find in the Solr UI that shows the ReversedWildcardFilterFactory actually did anything is in the Schema section under the collection. Then you have to select the field and then click the “Load Term Info” button to get details about the underlying terms. The screenshot below shows the terms for the a_txt_rev field.
Conclusion
Solr and the ReversedWildcardFilterFactory can help improve the performance of leading wildcard queries if they are absolutely required. When I’ve explained over the years that ReversedWildcardFilterFactory would solve leading wildcard issues, I hadn’t looked at the internals. This post forced me to look at the internals about how Lucene and Solr work with leading wildcards. I checked multiple versions of Solr (4.3.x, 4.10.x, 5.5.x, 6.3.x, and 7.5.x) initially thinking that the query was not using the reversed tokens. It wasn’t until I used a debugger to check that I could convince myself that the query was being handled properly. Better debug logging for this case would have helped tremendously.
Solr Setup Reference
I used the following to setup Apache Solr for reproducing all the screenshots above. There are also command line versions for gathering the same information programatically.
./bin/solr start -c
./bin/solr create -c test -n basic_configs
echo '1,abcdefg,abcdefg' | ./bin/post -c test -type text/csv -params "fieldnames=id,a_txt,a_txt_rev" -d
curl "http://localhost:8983/solr/test/select?q=*:*"
curl "http://localhost:8983/solr/test/select?q=a_txt:abcdefg&debug=true"
curl "http://localhost:8983/solr/test/select?q=a_txt_rev:abcdefg&debug=true"
curl "http://localhost:8983/solr/test/admin/luke?fl=a_txt_rev&numTerms=2"