Apache HBase - Snappy Compression
Overview
Apache HBase provides the ability to perform realtime random read/write access to large datasets. HBase is built on top of Apache Hadoop and can scale to billions of rows and millions of columns. One of the features of HBase is to enable different types of compression for a column family. It is recommended that testing be done for your use case, but this blog shows how Snappy compression can reduce storage needs while keeping the same query performance.
Evidence
Below are some images from some clusters where testing was done with Snappy compression. The charts show a variety of metrics from storage size to system metrics.
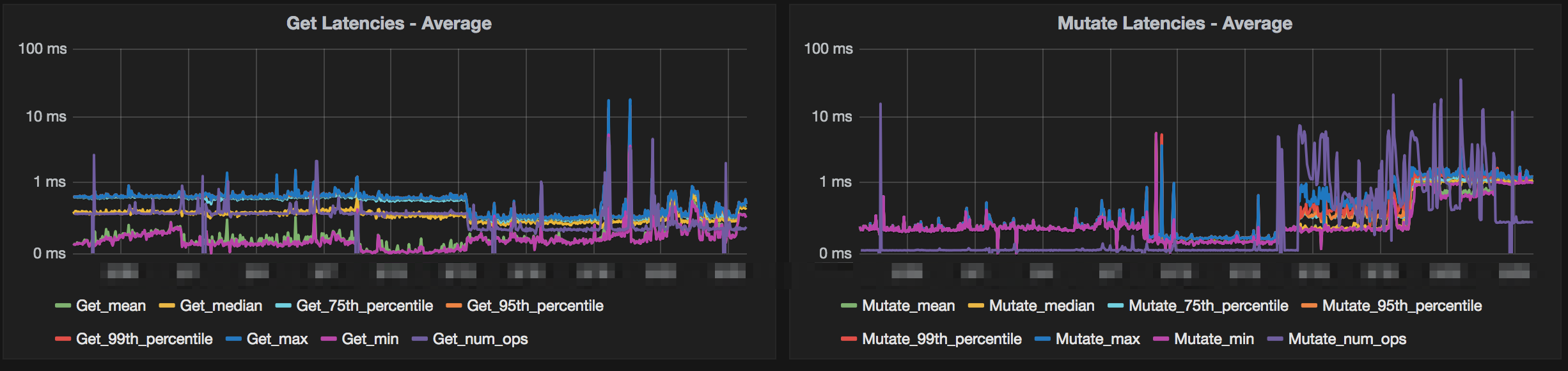
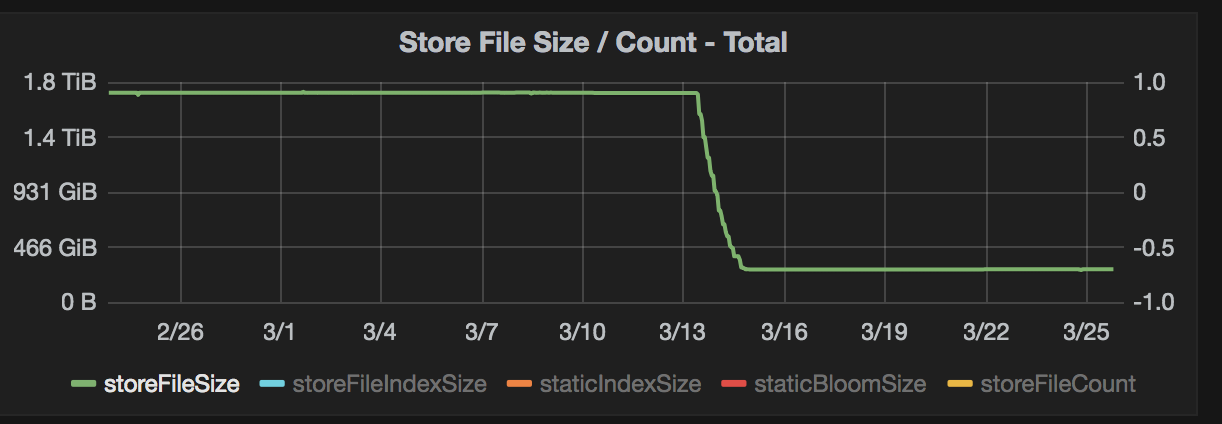
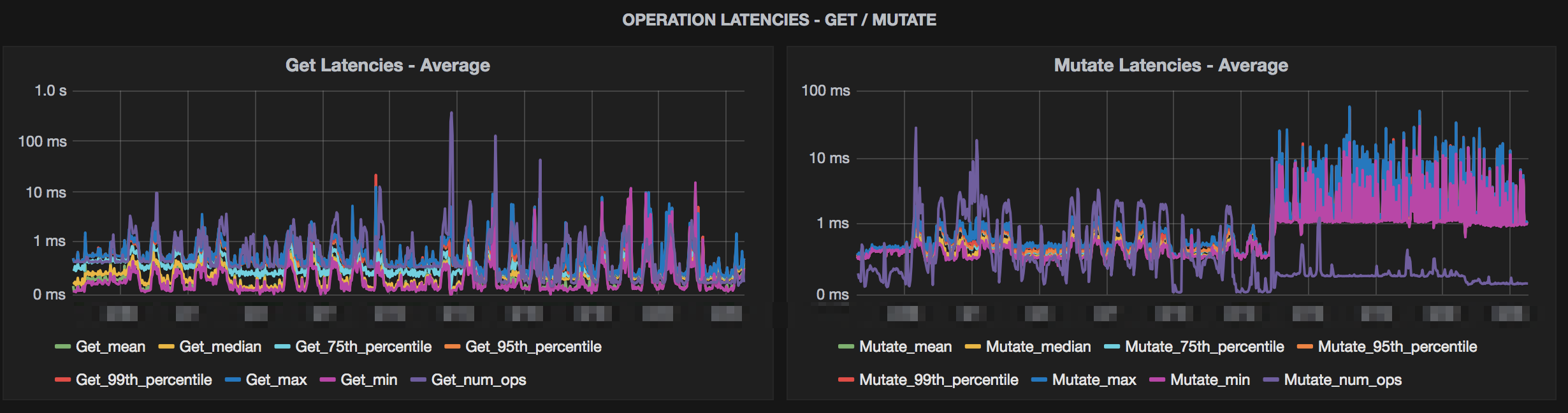
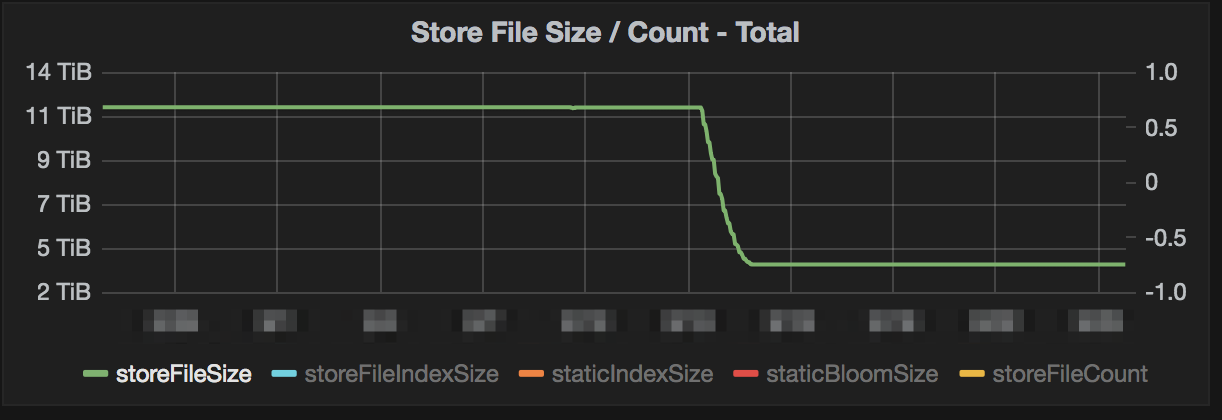
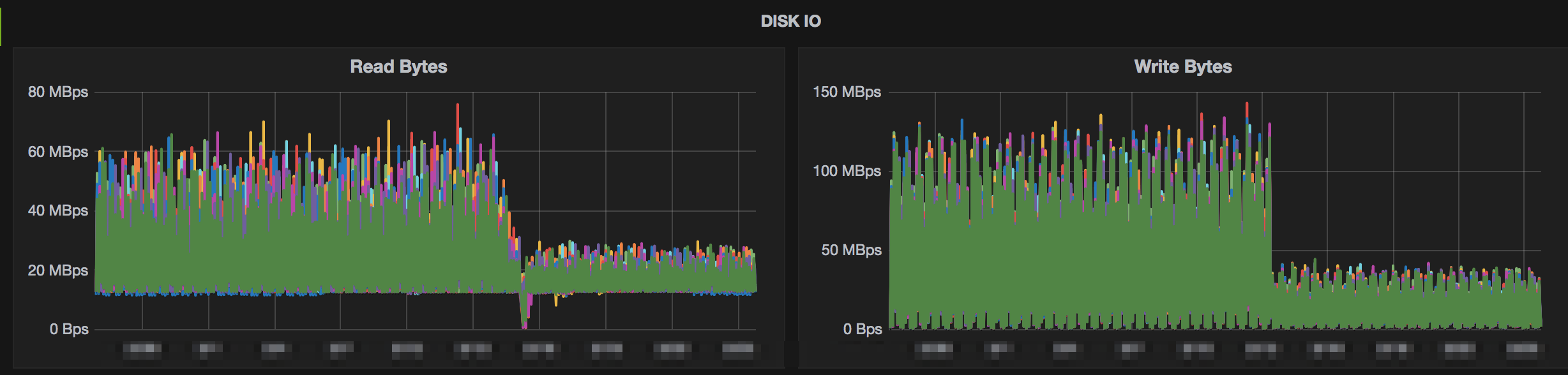
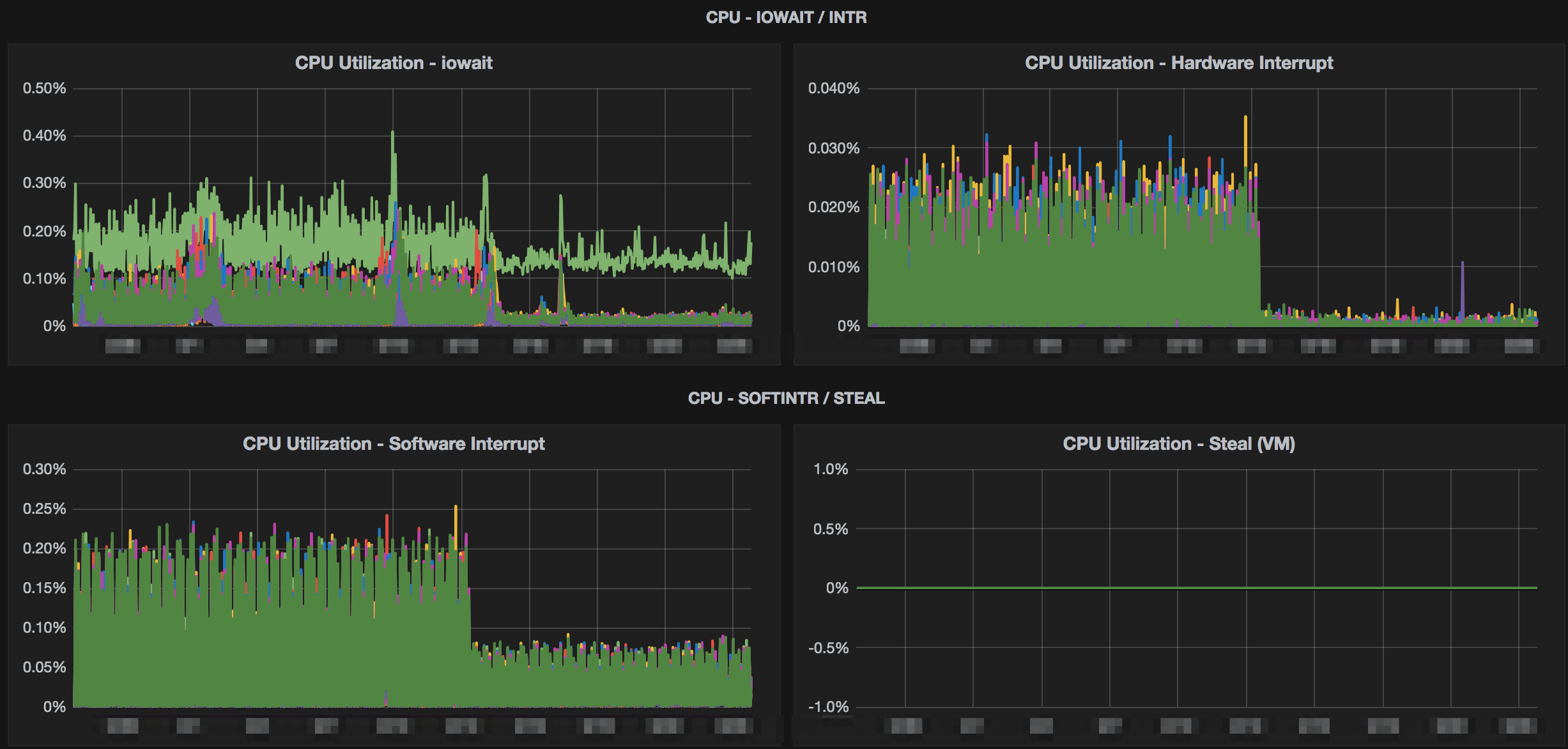
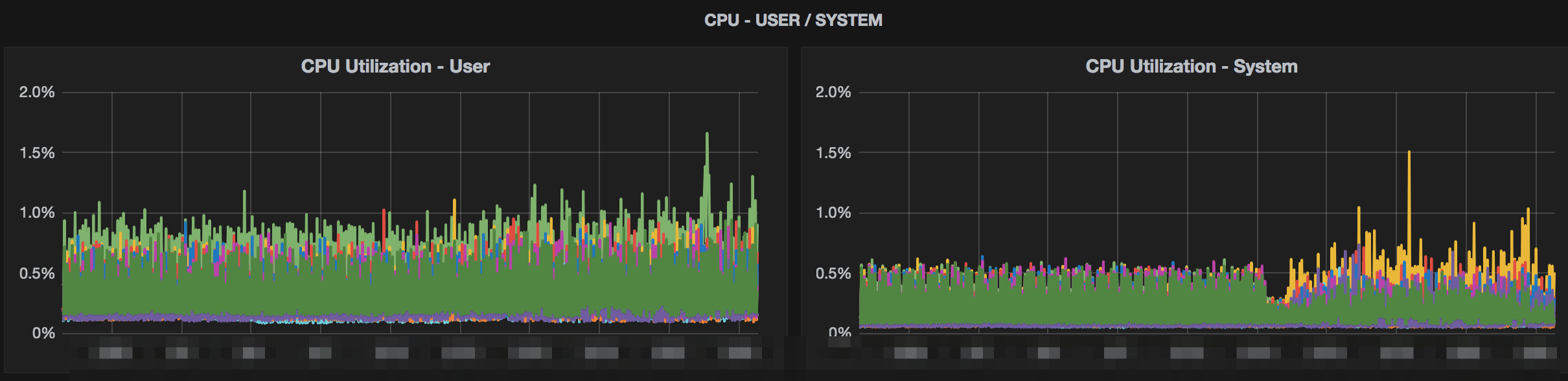
Conclusion
The charts above show >80% storage saving while only seeing a slight bump in mutate latencies. The clusters that this was tested on were loaded with simulated data and load. The production data matched this when deployed as well. This storage savings also helped backups and disaster recovery since we didn’t need to move as much data across the wire. References for implementing this yourself with more options for testing are below.
References
- https://community.hortonworks.com/articles/54761/compression-in-hbase.html
- http://hadoop-hbase.blogspot.com/2016/02/hbase-compression-vs-blockencoding_17.html
- https://blogs.apache.org/hbase/entry/the_effect_of_columnfamily_rowkey
- https://db-blog.web.cern.ch/blog/zbigniew-baranowski/2017-01-performance-comparison-different-file-formats-and-storage-engines
- http://blog.erdemagaoglu.com/post/4605524309/lzo-vs-snappy-vs-lzf-vs-zlib-a-comparison-of
- https://hbase.apache.org/book.html#compression
- https://hbase.apache.org/book.html#data.block.encoding.enable